
Blockstack is broadening the meaning of “Mining”.
Traditionally the term ‘mining’ in cryptocurrency refers to the process of contributing compute resources to the network and earning a reward. On the Blockstack network, however, instead of just ‘mining’ through computation, developers can “mine” by contributing apps to the ecosystem and making applications the community wants.
Blockstack’s App Mining program rewards decentralized application development. This post takes a deeper dive into how the game rewards work.
This post was prepared together with Pietro Ortoleva, Efe Ok, and Ennio Stacchetti, game theorists and behavioral economists from Princeton and New York University. This entry describes:
- How the scores from the App Reviewers (the entities submitting votes into the aggregation algorithm) are aggregated into a final score
- A payment scheme for the best performing apps
- Methods of evaluating the performance of the app review companies themselves after one year from the initial period
This post is a description of the general principles adopted for each of these steps. We refer to the technical report below for the details (including precise formulas) and a more complete technical analysis. You can also find a white paper and a few videos that provide further details.
Paper: An Aggregation Algorithm for Blockstack
The App Reviewers
Reviews of apps will be made by App Reviewers: Product Hunt, Democracy Earth, and a third one; for the purpose of this discussion, just as an example, we will use Usertesting.com. Each App Reviewer reports different scores, using different criteria that are combined into a final ranking, with the hopes of producing a more robust, less game-able version of App Mining. There presumably would be more App Reviewers added in the future, where this game design would remain applicable.
How to aggregate the App Reviewer scores into a final score
The Raw Data
From each app reviewer, we receive multiple scores, one for each criterion.
Step 1: Normalizing the Scores
By bringing the scores to the same units of measurement, they can be aggregated more meaningfully.
In the first step we take all the scores that we receive from all reviewers and normalize them: first, by subtracting the average raw score in each category, second by dividing by the standard deviation of the raw scores in that category.
This normalization avoids giving excessive weight to those app reviewers that tend to give more extreme raw scores.
The resulting normalized score of an app tells us to what extent the score of that app is above or below the mean score, measured in standard deviation units. For instance, the normalized score of 0 means that the corresponding raw score is exactly the average of all raw scores (of the same type). On the other hand, a normalized score of −1 means that the corresponding raw score is one standard deviation below the average raw scores of the same type (placing it roughly on the bottom 16% of all scores), and a score of 1/2 means that the corresponding raw score is one half standard deviation above the average raw scores of the same type (placing it roughly on the top 30% of all scores).
Step 2: Extension of Normalized Scores to Incorporate Missing Data
If there is missing data from an App Reviewer, this is the process for handling it.
At this stage of the procedure, we turn to those apps that have not received any votes in Democracy Earth, or were not evaluated on a given category or by a given app reviewer. As a general principle, we assign −1 as the normalized score of such apps for every score they miss. Given the nature of normalization we have introduced in Step 1, this means that these apps receive the score of the app that sits (in terms of its raw score) exactly one standard deviation below the average. Thus, the procedure punishes these apps, but does not necessarily give them the worst evaluation. (Moreover, some of this punishment is alleviated in Step 5, where we aggregate the normalized total scores of the apps through the evaluation periods.)
Step 3: Aggregation within the App Reviewers
In this step we aggregate the scores for an app within each App Reviewer to obtain “the” reviewer’s score of that app.
We now have multiple normalized scores for each app reviewer — recall that each app reviewer reports multiple raw scores in different categories. In the case of a potential App Reviewer like UserTesting.com, there may be four scores, one for each category. In the case of Product Hunt, we have two scores, one from the team and one from the community. In the case of Democracy Earth, we again have two scores, one measuring the “desirability” of the app, and one measuring the “attention” that app receives in the market. In this step we aggregate the scores that an app has received from any one of these reviewers into a single score to obtain “the” reviewer score of that app. We do this simply by taking a weighted average of the reviewer’s scores.
Step 4: Aggregation across the App Reviewers
In this step we aggregate the normalized scores that an app has received across all of the App Reviewers.
The objective is to do this in a way that reduces the impact of a single app reviewer score on the total score. In general, a main concern for the overall procedure is the potential for manipulation (such as vote buying, etc.). Our method reduces the incentives to do this by making such manipulations costly by means of adopting a nonlinear aggregation method across reviewers.
Put more precisely, instead of taking simply the average of the reviewer-aggregate scores determined in Step 3 above, we pick a function F to transform each score, and only then take the average of these transformed values. This will be the aggregate score obtained in this step. The function F is chosen so that it is strictly concave for positive (normalized) scores, and strictly convex for negative (normalized) scores. (See the technical report for the exact formula.) It has an S-shape quite similar to the one below:
The function F
To illustrate the point of utilizing such a function F, suppose App i wishes to increase its overall ranking by 0.3. Given the (convex) payment scheme we suggest below, this may be profitable. (For, small upward shifts in the mid ranks make relatively small monetary returns.) Now, suppose that the original (normalized) score of the app from a certain reviewer is, say, 0.2. Suppose for concreteness that the function F above 0 is the square root. Then, the formula above says that to increase its full score by 0.3, the app would have to increase its score from that reviewer by 1.81: recalling that scores are normalized and that 1 is the standard deviation, this means manipulating that score from that reviewer very substantially. Importantly, the higher the app’s original score, the more unfeasible is to manipulate the algorithm from a given reviewer. If, for instance, the score of App i from Democracy Earth (DE) were 0.8, then the app needs to increase its DE score to 3.2 (in standard deviation units) which, for all practical purposes, means buying the votes of the entire community.
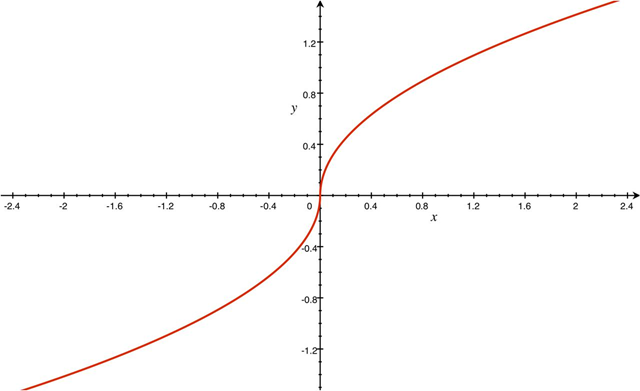
On the other hand, with S-shaped functions like the one above it is a bit easier to have small manipulations for scores near the average scores. But given the payment scheme (see below), this may not be very profitable.
Step 5: Intertemporal aggregation, only for periods after the first
Since app developers will continue to improve their apps, and since the past and present evaluations of their app contains valuable information, we can continuously account for this with a “memory” function.
For the initial period, the algorithm stops here. For periods after the first, however, we introduce a “memory” for the algorithm, because the previous scores of an app may contain valuable information that one should not lose. We thus adopt a scheme of discounted aggregation of scores over time.
Specifically, we will discount previous scores by a factor of 0.8.
The algorithm at this stage works as follows. Suppose we are in the second period. Consider the scores of the app obtained in Step 4 above in the initial period, call it s(1). Suppose the score of this app obtained in Step 4 in the second period, is s(2). Then, we obtain a total score for period 2, Total(2) as
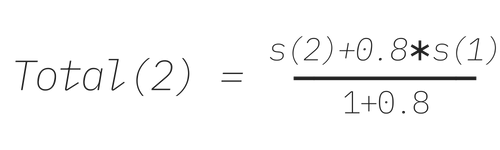
In general, to compute the total score for period m, Total(m), we use the following recursive formula:
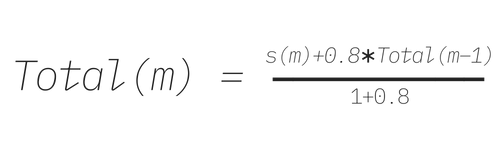
According to this algorithm, older scores are accounted for, but discounted.
New Apps
In some periods new apps may enter the pool. It is important that the reviewers are made aware when a new app arrives, and that they make sure to include it in their evaluation process as soon as it arrives. This is crucial for the method that is applied for missing data pertaining to a new app.
In the case of new apps, the algorithm will compute a score for new apps as it this was the first period in the algorithm was run. Because the total scores of the other apps are normalized, it will thus be comparable, and new apps will not be disadvantaged.
The payment scheme for Apps
App developers must be paid out each month in accordance to their app’s ranking, where the higher your app is ranked the more you will earn.
We propose to use the following payment scheme. Blockstack sets total budget M, a percentage p, and a maximum number of paid apps n (which could be more than the total number of apps under consideration). Then, the scheme pays the fraction p of M to the first app; the fraction p of the remainder to the second app; and so on. In particular, the second best app is paid
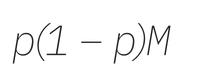
while the nth app is paid
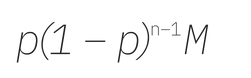
This proceeds until app n is reached and/or there are no more apps.
We adopt p=20% for the pilot of App Mining.
Dealing with Ties
It may happen that two or more apps would get the same final score, and hence tie for a position in the final ranking. In this case, the payments to the apps are equally distributed among the apps that are tied, and the total amount to be shared is the one that would have been paid to all these apps if there was no tie.
For example, recall that the first app receives a payment of p*M, and the second app a payment of p(1 − p)M. Now suppose that two apps are tied for the first place. Then the two apps share equally a total of pM + p(1 − p)M.
Criteria to Evaluate App Reviewers
The below criteria are suggestions for evaluating App Reviewers and could be used for voting or for further incentivization.
We suggest three criteria to evaluate the app reviewers. All three criteria have advantages and disadvantages. The community will be given the outcome of the rankings according to all three criteria – the third one being run both globally and by broad categories – in order to make their evaluations.
Criterion A: Agreement with the Final Ranking
A first possible criterion is to investigate whether a reviewer’s score is similar or different to the final, aggregate one, obtained after 12 months. There are two reasons to consider this final score as a benchmark. First, it is the ranking resulting from the most information – it aggregates a number of different reviews repeated over time – and may thus be considered the most accurate. Second, because these final scores will not be known until much later, it is harder for app reviewers to adapt to them beyond reporting their genuine evaluation of the app.
Thus, we can construct a score for each reviewer which is minus the sum of the square distances between the score of each app in each period by that reviewer, and the final aggregate score of the app.
There are two limitations of this criterion. First, because it punishes the variance with respect to a final score, it punishes reviewers with scores that are highly variable over time. For example, if the final score of an app is 1, a reviewer that reports 1 all the time has a higher score than a reviewer whose scores for that app alternate between 0.8 and 1.2.
The second limitation is that it discourages reviewers to use an approach that is very different from that of the other reviewers. For example, suppose that two app reviewers follow methodologies that lead them to be largely in agreement, while a third one tends to give uncorrelated scores. Then, the last reviewer is more likely to receive a lower reviewer-score, unless his method is better at predicting the final score.
Criterion B: Agreement with Objective Criteria
A second measure with which reviewers may be evaluated is by comparing their scores with external, objective criteria. For example, it could be possible to compute a score of different apps based on external financing, or based on number of monthly active users. One can then compute whether each reviewers’ score in each period agrees, or not, with this final objective ranking.
This is constructed like Criterion A above, except that uses as a comparison point, instead of the total final score, the objective criterion (also normalized like in Step 1 of our algorithm).
As in the case of Criterion A, this criterion rewards reviewers with scores that have been highly consistent over time. It also rewards those who have been accurate in predicting the apps that are financed the most/least, or have the most monthly active users.
Criterion C: Spotting Top Apps
A third criterion to evaluate reviewers is their ability to spot great apps early. This could be a particularly desirable feature, as it may be particularly important for apps with great potential to receive funds early so that they reduce their risk of disappearing and continue to grow.
Consider the apps that are in the top 10% with respect to these total, final scores; let T denote the set of all such apps. We want to give credit to a reviewer that gives a high score to apps in this group earlier on. Thus, we can simply add the number of times in which a given reviewer places each app in T in the top 10% of its own aggregate ranking (computed in Step 3 of our algorithm).
Note that reviewers with scores that fluctuate a lot over time may (although need not) have an advantage according to this criterion. Note also that this measure does not depend on the actual score that apps are given either by the reviewer or in the final ranking: all that it matters is the ability to identify top performers, even if their relative rank is different from the final one. This is markedly different from the approach used in the other two criteria above.
Finally, let us note that this criterion can be applied to the whole set of apps, or it can be run category by category. The latter method could be particularly useful in that it may incentivize reviewers to spot the good apps even in categories that are not too popular, thereby ensuring that the available apps are consistently good across the board.
We hope this explainer was useful to you. If you would like to continue the discussion about App Mining, head over to the forum. If you are interested in entering your app into the App Mining program, visit app.co/mining.